GenevaERS Architectural Direction Update
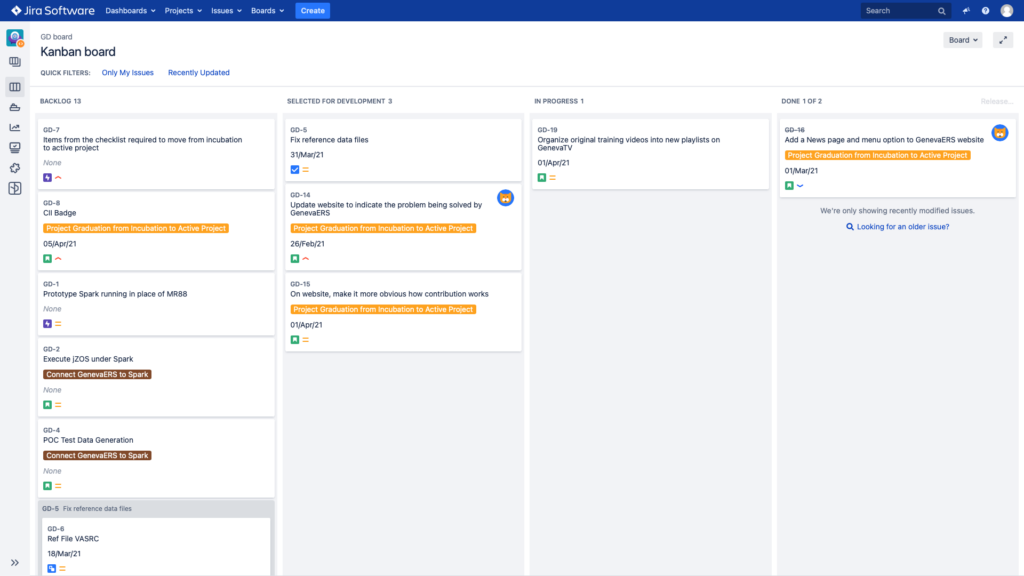
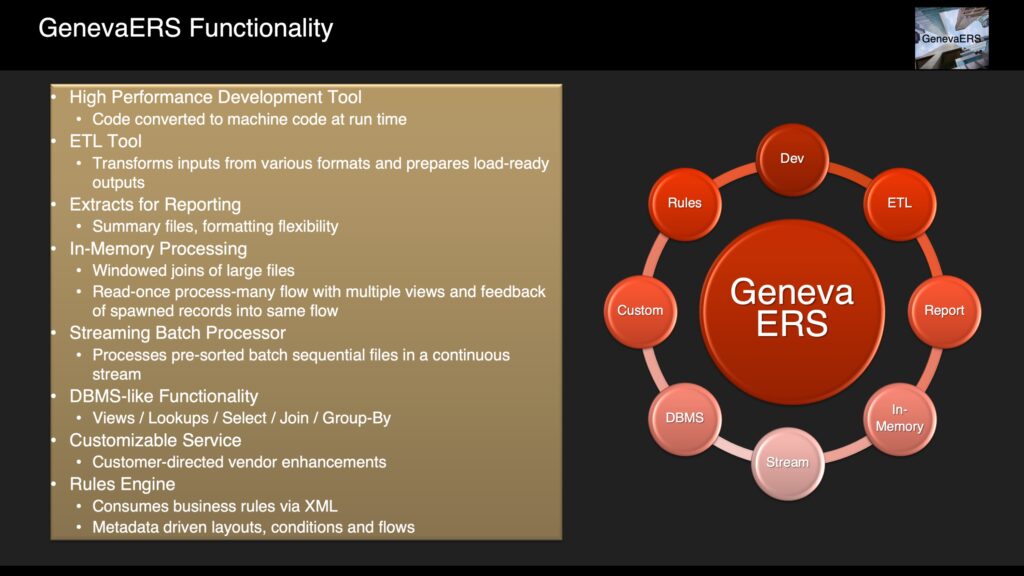
Based upon the Active Project Status achieved in August 2021, the project team reviewed and updated it architectural direction. The following slides give a sense of progress made to date...

Based upon the Active Project Status achieved in August 2021, the project team reviewed and updated it architectural direction. The following slides give a sense of progress made to date...
On August 12, 2021, the Technical Advisory Committee of the Linux Foundation’s Open Mainframe Project approved GenevaERS’s promotion from an incubation to active project. The following were the points made...
March 15, 2021 is a milestone of sorts: it is 25 years to the day later than predicted by one pundit as the date the last mainframe would be turned...
The GenevaERS project is teaming up and providing support for two other Open Mainframe Initiatives; Polycephaly and the Open z/OS Enablement or OzE project. Polycephaly Polycephaly is intended to be...
Organization of the project continues, but much progress has been made. Check out the Community Repository on GitHub, and its Governance and Technical Steering Committee Checklist to see what’s been...
On Thursday July 9th, GenevaERS was approved an Incubation Project under the Linux Foundation’s Open Mainframe Project. Comments from the approving Technical Advisory Committee included (paraphrased): “This project showcases the...
The GenevaERS has applied for incubation status under the Linux Foundation’s Open Mainframe Project. The application can be viewed here. To graduate from Incubation Stage, or for a new project...
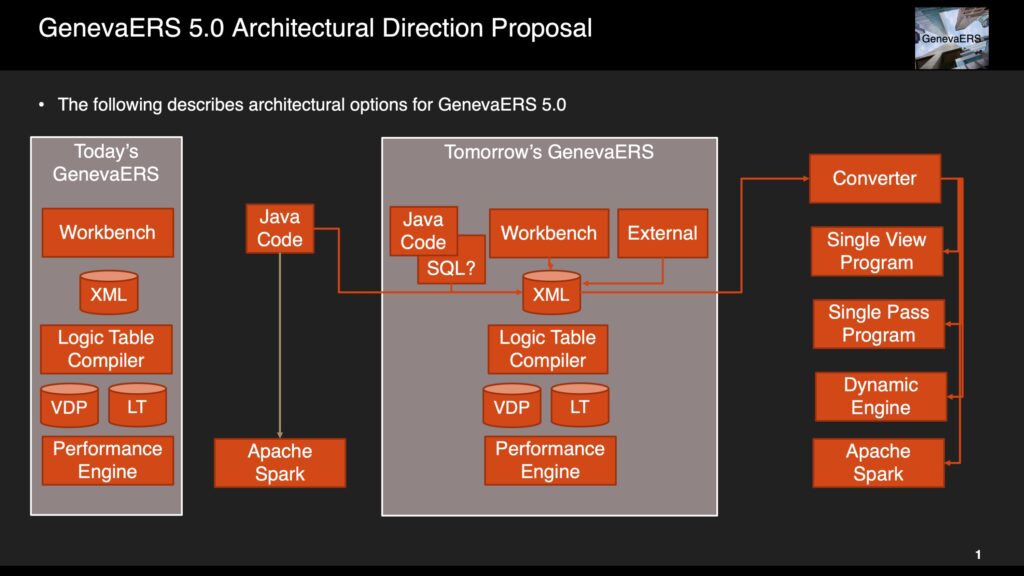
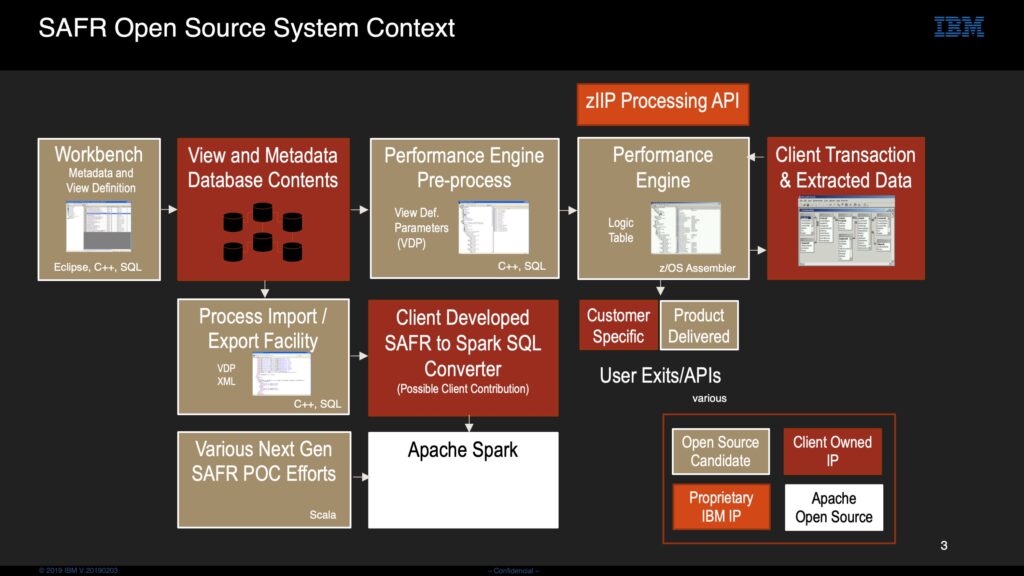
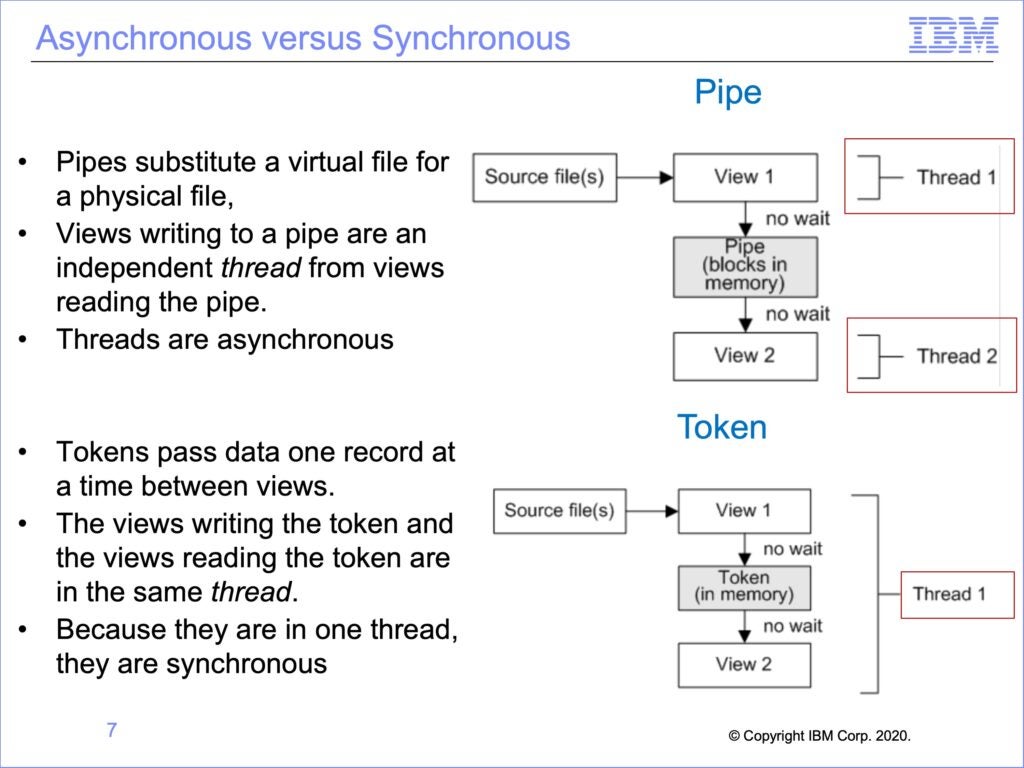
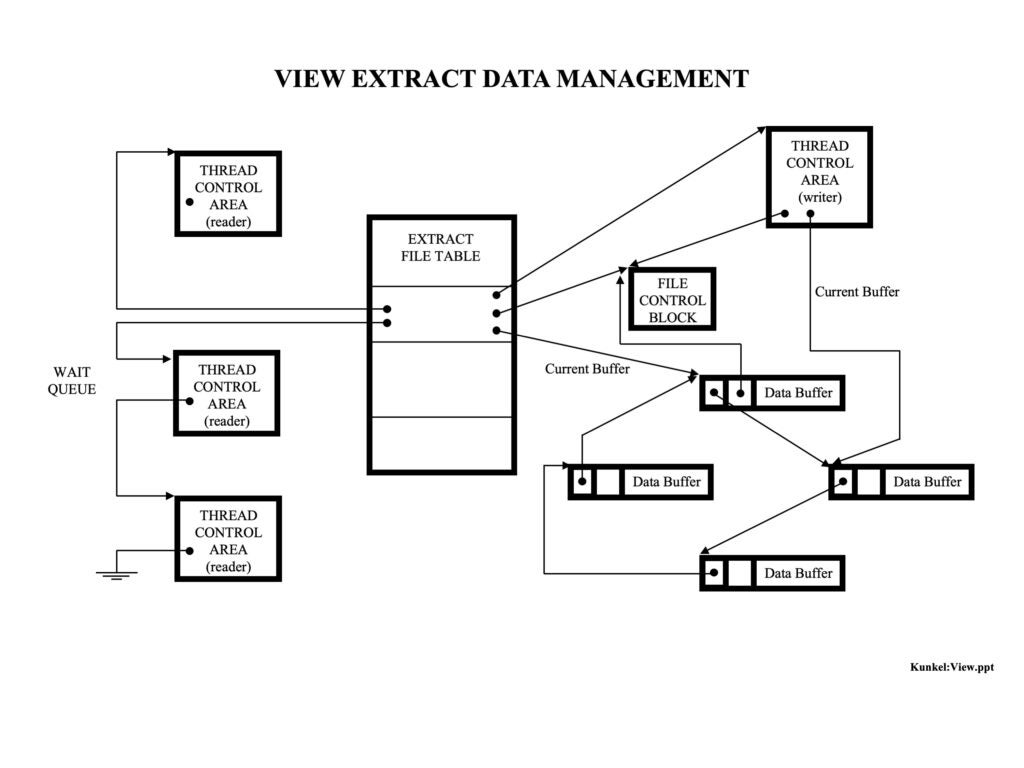
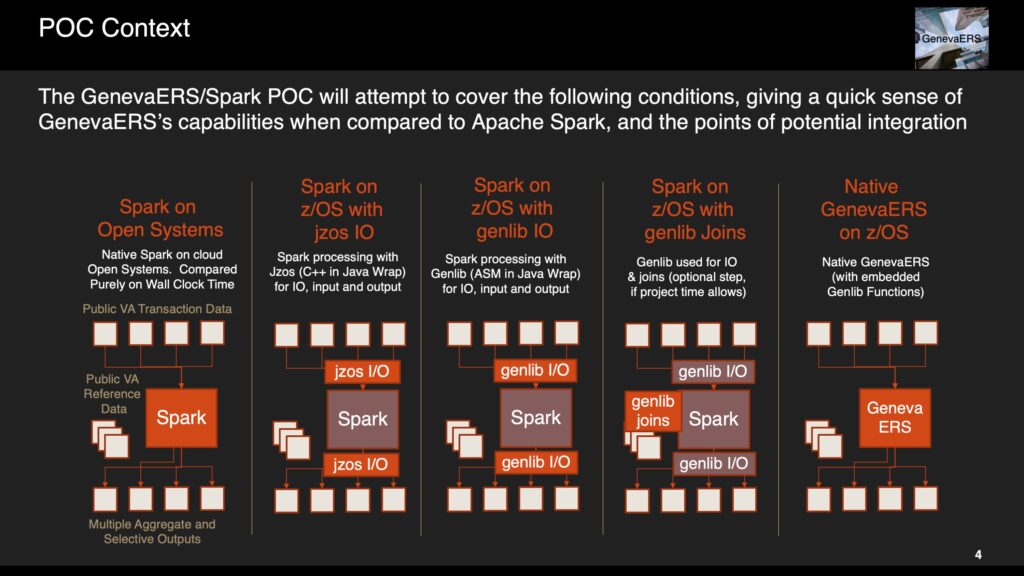
The following are some initial thoughts on the next version of GenevaERS as an Open Source project might go: Workbench Currently the only way to specify GenevaERS processes (called a...
Existing customers have been working on using GenevaERS metadata in related processes outside of GenevaERS. Our first contributor to open source, Sandy Peresie, took on the challenge of building a...
The following is notes about the beginnings of GenevaERS, as compiled by Randall for a reunion of team members in April 2019 in Chicago. The content is supplemented by the...
The following update was provided to GenevaERS/SAFR alumni in June 2020, reflecting the work that has progressed for the last several years.
The following slides were used with existing customers to explain the rationale for SAFR Open Source in April 2020
The slides used in the following video are shown below: Slide 1 Welcome to the training course on IBM Scalable Architecture for Financial Reporting, or SAFR. This is Module 22,...
The following is an R&D effort to define the next generation of SAFR, composed by Kip Twitchell, in March 2017. It was not intended to be a formally released paper,...
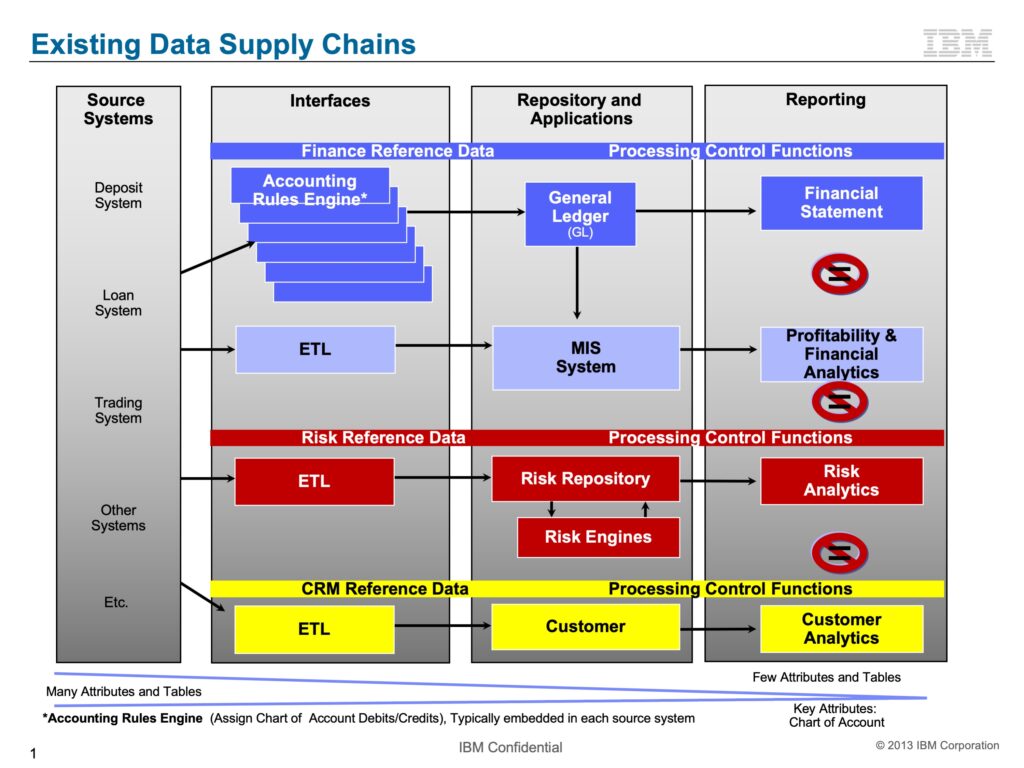
The following slides were developed while consulting at 12 of top 25 world banks about financial systems from 2013-2016. Although not specific to GenevaERS, it delineates the causes of the...
The slides used in the following are shown below: Slide 1 Welcome to the training course on IBM Scalable Architecture for Financial Reporting, or SAFR. This is Module 21, The...
The slides used in the following video are shown below: Slide 1 Welcome to the training course on IBM Scalable Architecture for Financial Reporting, or SAFR. This is Module 20,...
The slides for the following video are shown below: Slide 1 Welcome to the training course on IBM Scalable Architecture for Financial Reporting, or SAFR. This is Module 19, Parallel...
The slides for the following video are shown below: Slide 1 Welcome to the training course on IBM Scalable Architecture for Financial Reporting, or SAFR. This is Module 17, Format...
The slides for the following video are shown below: Slide 1 Welcome to the training course on IBM Scalable Architecture for Financial Reporting, or SAFR. This is Module 18, Extract...


© 2026 GenevaERS. Copyright © Open Mainframe Project. The Linux Foundation® . All rights reserved. The Linux Foundation has registered trademarks and uses trademarks. For a list of trademarks of The Linux Foundation, please see our Trademark Usage page. Linux is a registered trademark of Linus Torvalds. Privacy Policy and Terms of Use.