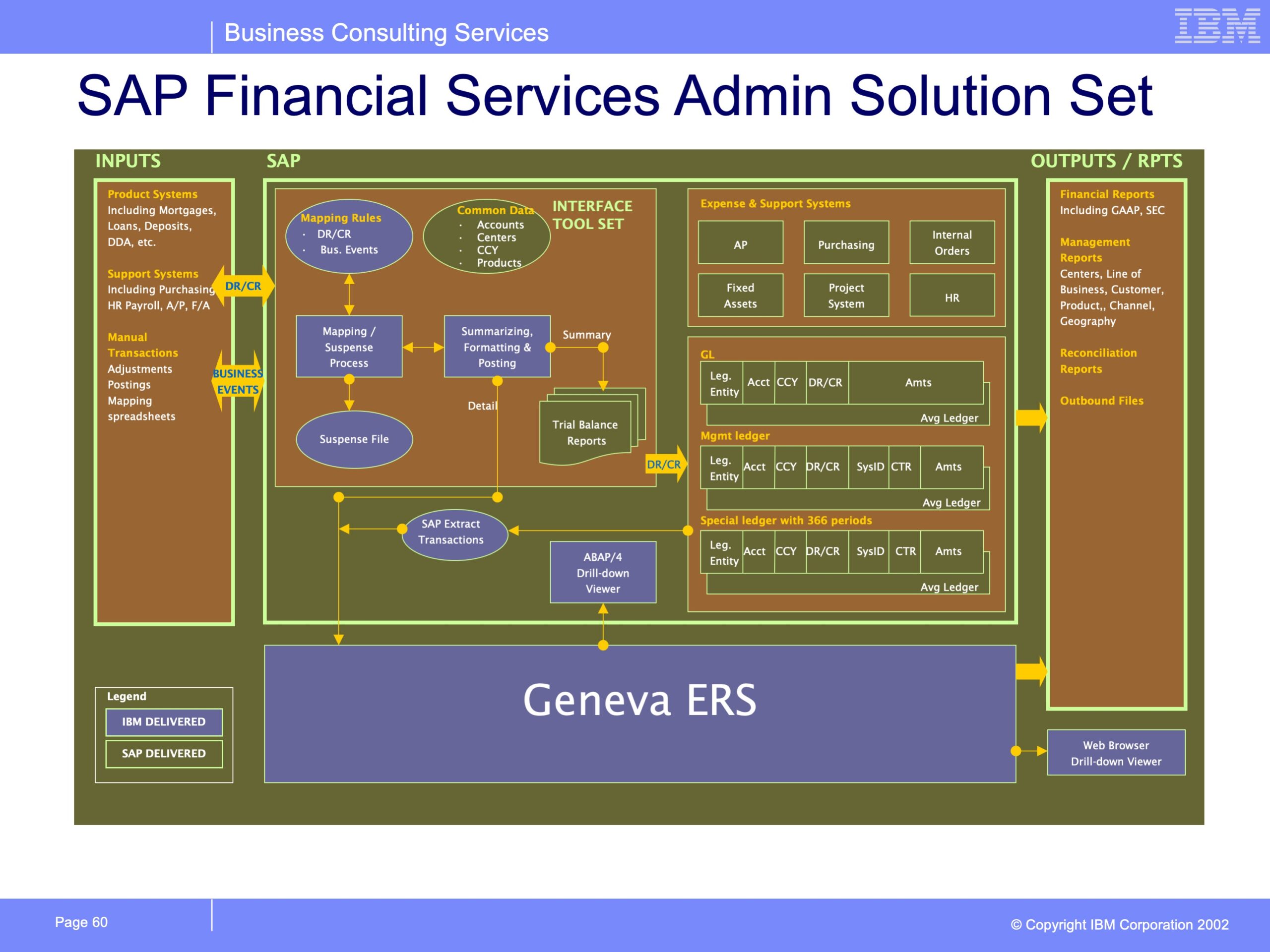
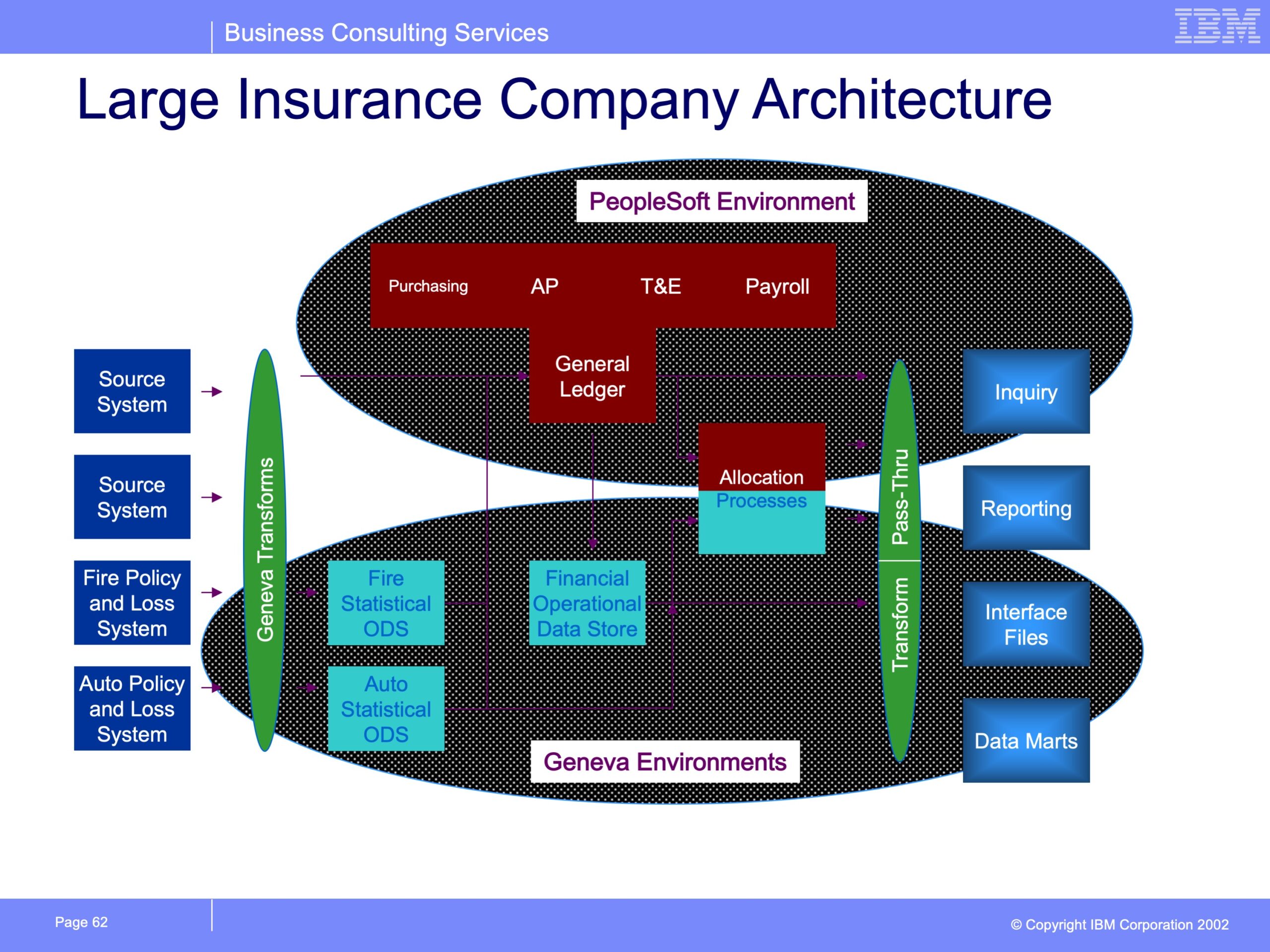
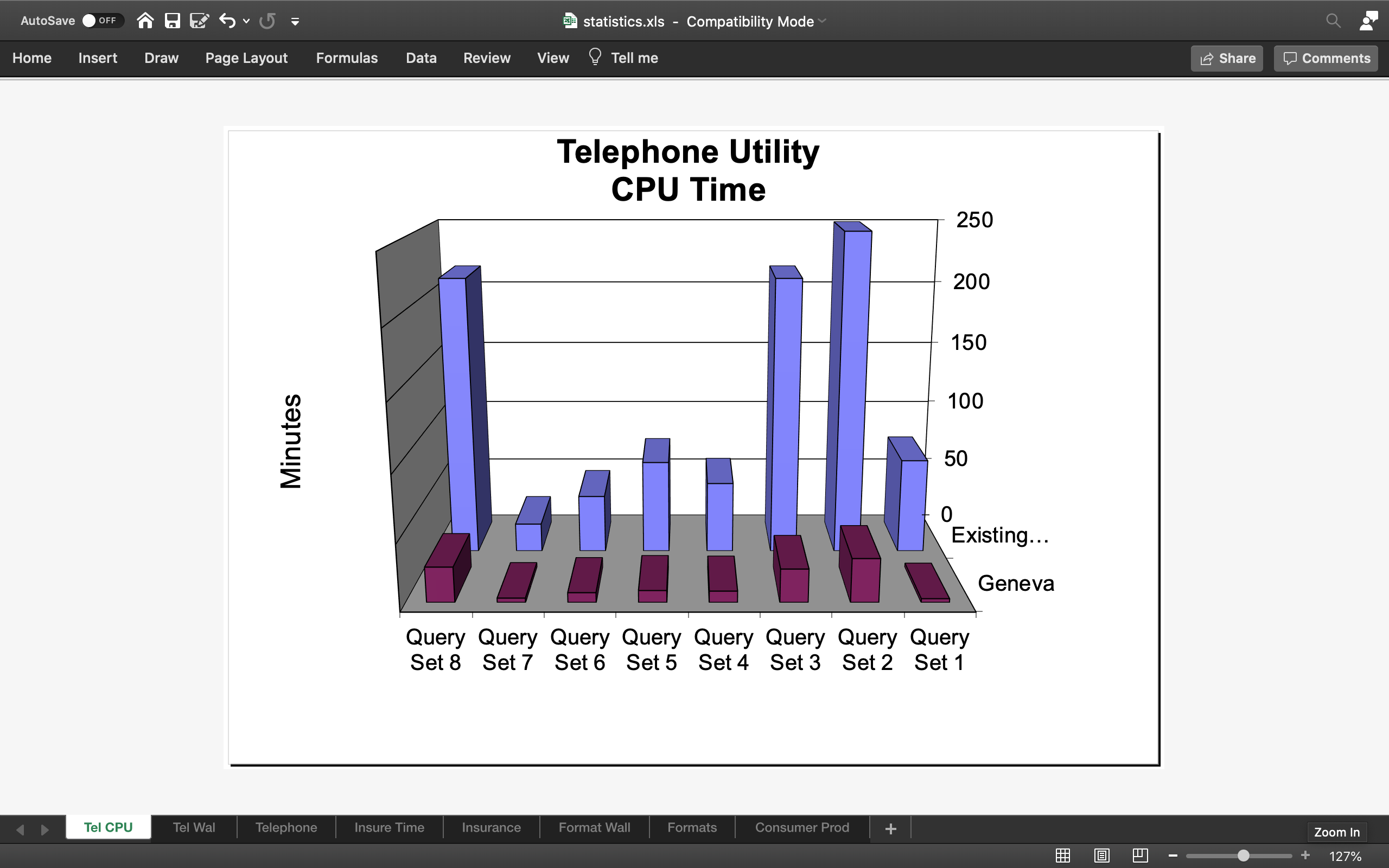
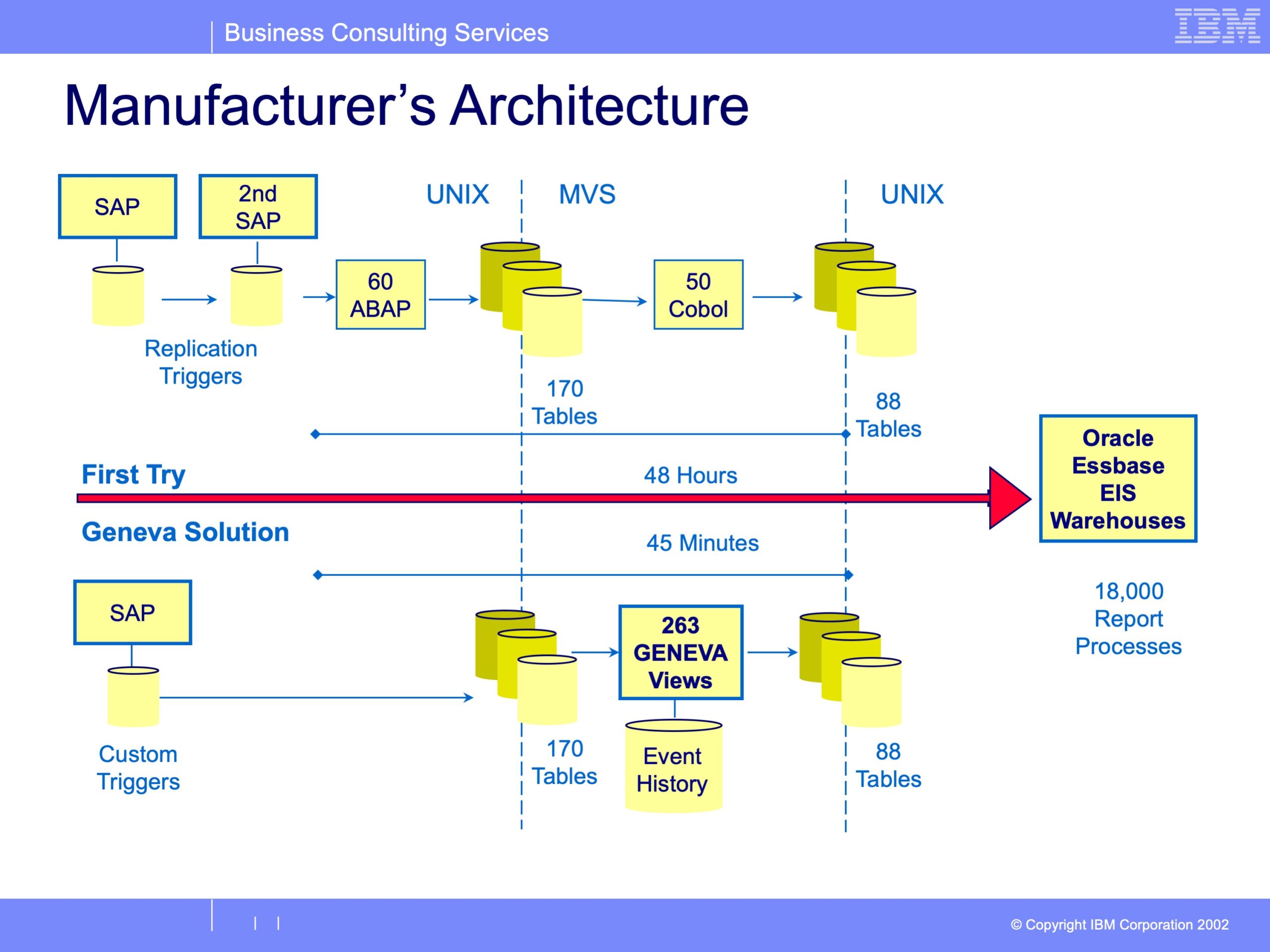
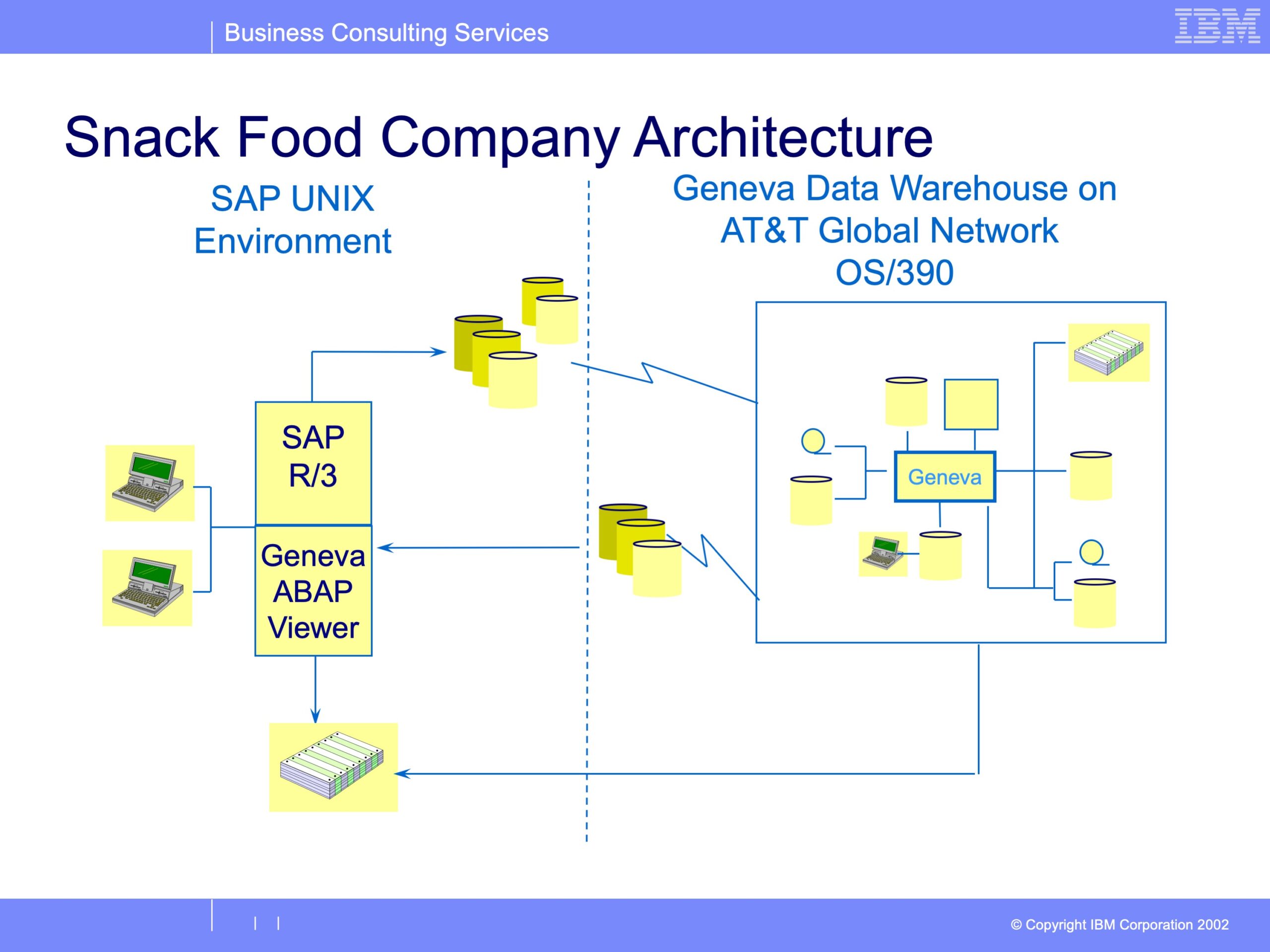
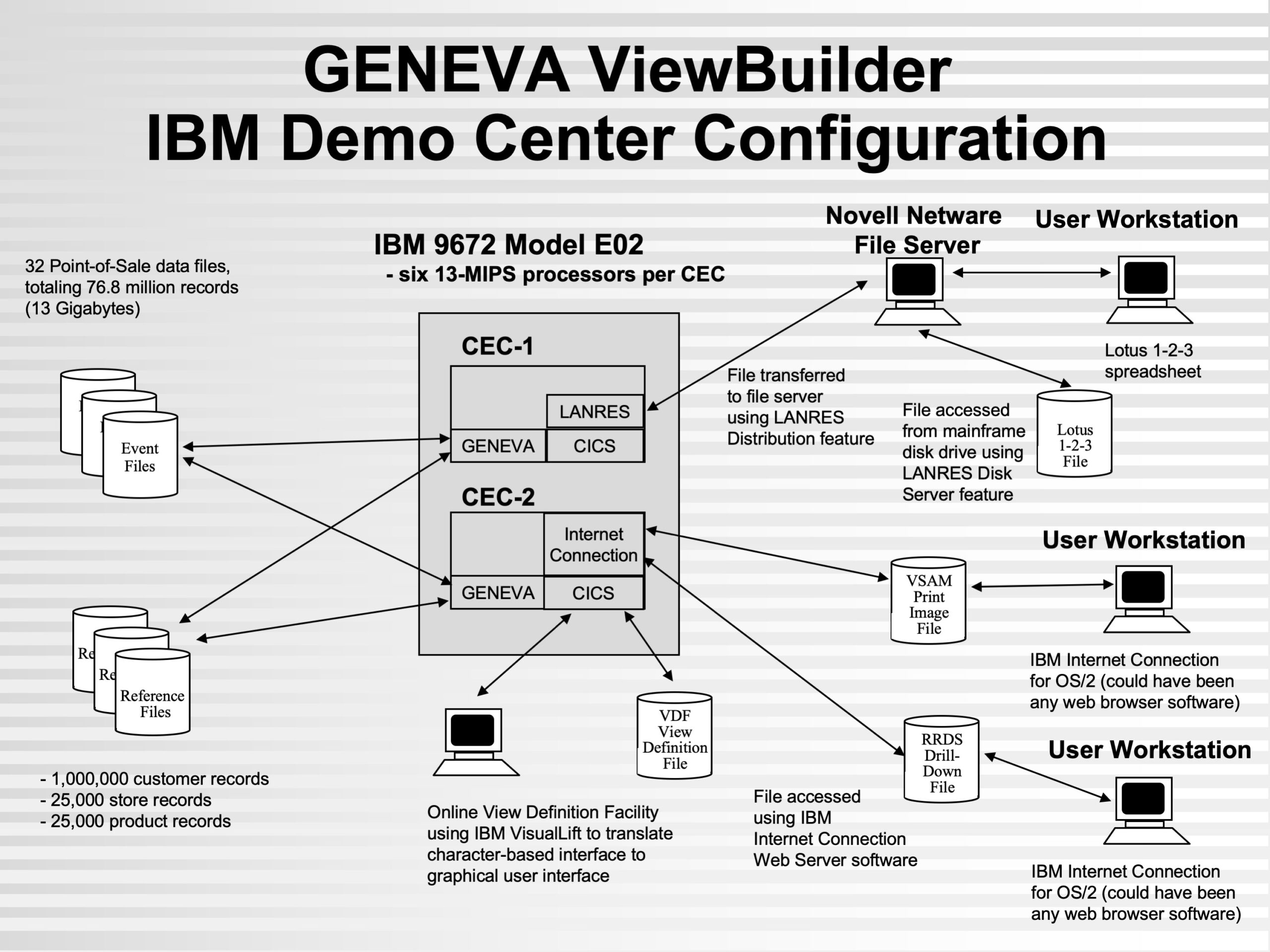
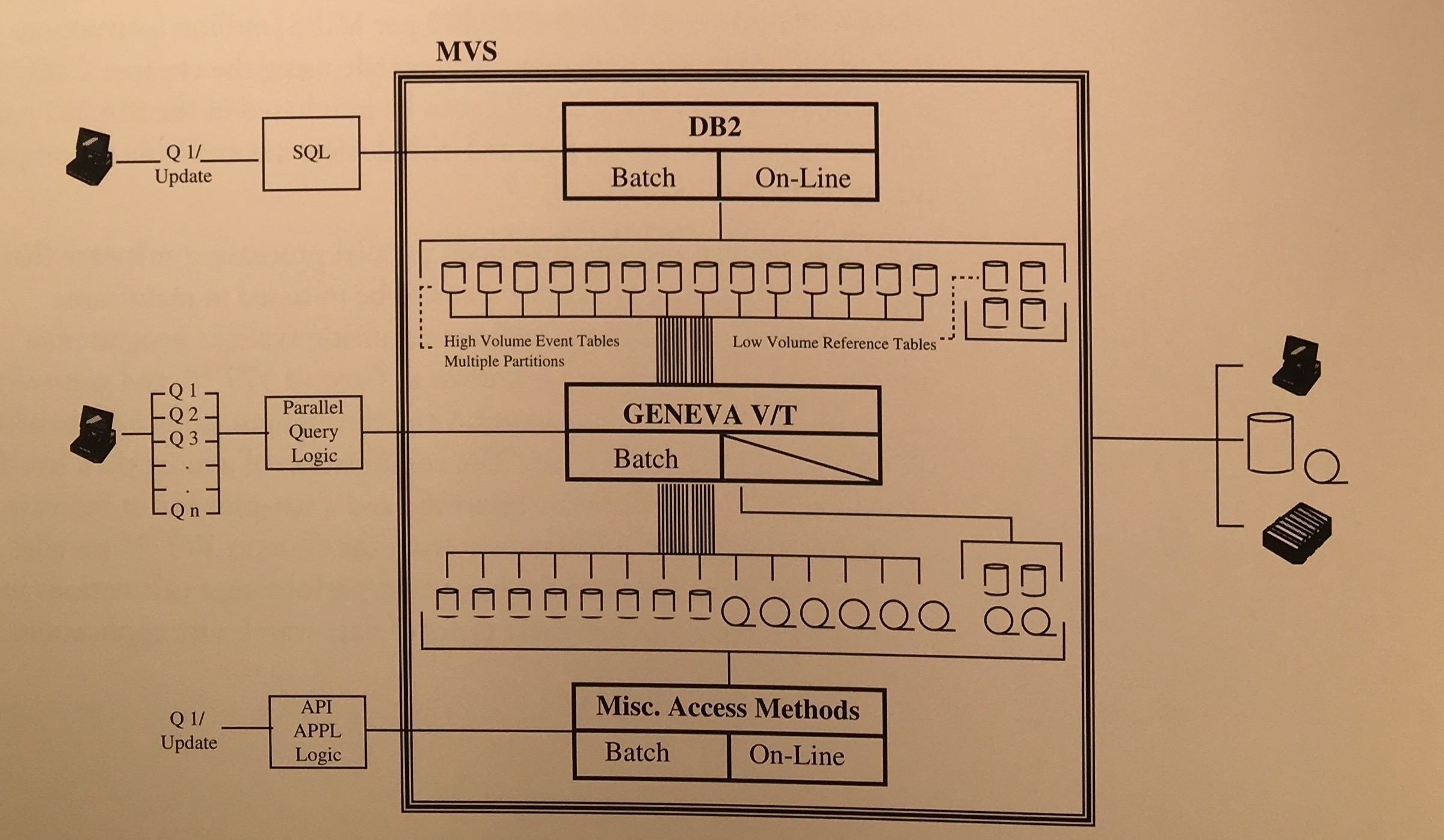
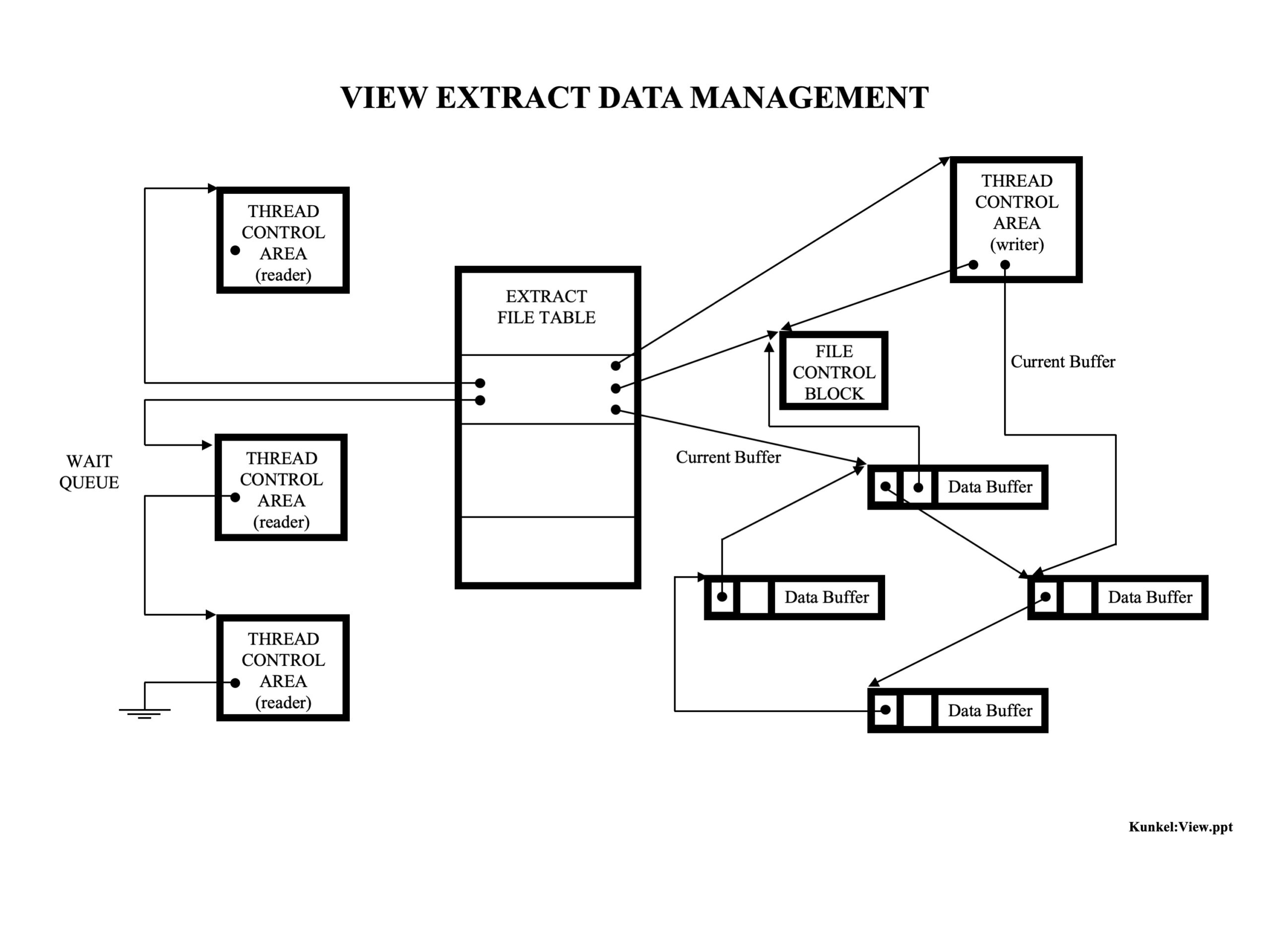
© 2026 GenevaERS. Copyright © Open Mainframe Project. The Linux Foundation® . All rights reserved. The Linux Foundation has registered trademarks and uses trademarks. For a list of trademarks of The Linux Foundation, please see our Trademark Usage page. Linux is a registered trademark of Linus Torvalds. Privacy Policy and Terms of Use.