

by Richard K. Roth, Principal Price Waterhouse LLP, Sacramento, California
November 8, 1995
[More about this time can be read in Balancing Act: A Practical Approach to Business Event Based Insights, Chapter 20. Parallelism and Platform.]
Why Parallel Processing?
Data warehouse applications differ in a basic way from traditional transaction processing and reporting applications:
- Transaction processing applications usually process a day’s or a month’s activity, then archive the detail and clear out the files to prepare for the next day’s or month’s activity. Reporting functions for these applications are primarily limited to supporting the operational and clerical aspects of the narrow functional area addressed by the application for just the days or months that are open. Even for “high” volume applications (e.g., call detail billing) the volume never really gets “large” because of the archiving process.
- Data warehouse applications tend to deal with “large” volumes of data since their primary purpose is to perform a retrospective analysis of the cumulative effects of transaction processing over time. Some uses for data warehouses have similar characteristics to transaction processing applications in that specific requests may only require access to small amounts of data
(e.g., an individual customer’s profile and particular month of call detail activity). However, most analytical uses of data warehouse information require scanning large partitions of the warehouse to identify events, or customers, or market segments that meet particular criteria. It is in the scanning kinds of uses where the basic architecture for building transaction processing systems breaks down when applied to data warehouse applications.
The basic architecture for most transaction processing applications relies on indexed access to a few records in large files for purposes of validation or update (DB2 primarily is an indexed access method). The advantage is that if you only need to access or update a few records, and you can find the records needed through an index, a lot of time can be saved by touching only the records required rather than searching through all the records just to find the few that you want. In general, indexed access works at about 200,000 bytes per second (about an hour and a half per billion). So, as long as the transaction processing or reporting involved only requires that single billions of bytes be touched in the process once a processing cycle, indexed access is sufficiently fast for the purpose.
Data warehouses, however, can have tens, hundreds, or thousands of billions of bytes (gigabytes). In addition, the more detailed the data warehouse, the more difficult (impractical) it is to keep indexes on all the fields that might be needed to find the records. Consequently, using indexed access methods to process data warehouses could take hours or days, depending on size and arrival rate of processing requests. And the practical effect in many cases is that, under the covers, the indexed access method ends up doing a sequential scan of the files.
Sequential access methods are the basic alternative to indexed access methods. The advantage of sequential access is that it is very fast (1-20 million bytes/second depending on hardware and software configuration) compared to indexed access. Since much of the processing that goes on with a data warehouse is sequential anyway, it makes sense to take advantage of this speed where possible. Further, if the processing can be organized so that multiple sequential table scans can be initiated in parallel[1] rather than serially, enormous amounts of data can be scanned in a relatively short period of time (at 4 million bytes/second, a gigabyte can be read in about 4 minutes; if 40 of these sequential threads were started in parallel, half a trillion bytes could be read in an hour). The mathematics of parallelism really add up for data warehouses.
What are the practical alternatives for implementing parallel processing applications?
There are two basic approaches to achieving parallelism in processing:
- Specialized hardware architectures (i.e., massively parallel processing “MPP” computers) can be used that initiate parallel scans on separately paired CPU and disk assemblies (known as “shared nothing environments”). Teradata and Tandem are examples of two companies that manufacture computers in this class.
- Software can be used to initiate multiple parallel scans on computers that share a common pool of disk and tape devices (known in two groups as mainframes and symmetric multi-processor “SMP” machines). IBM, AMDAHL, and Hitachi are companies that manufacture mainframes. Hewlett Packard, Silicon Graphics, and Sequent are examples of companies that manufacture SMP machines.
Until recently, the MPP hardware approach was almost always the most cost-efficient way to achieve parallelism for data warehouse processing. MPP machines are manufactured using CMOS processor technology and work with disk drives that historically have been less costly than a corresponding mainframe configuration. In addition, the only software available for the mainframe that really exploited its parallel processing, multi-tasking, high data bandwidth capabilities were CICS, DB2 and JES, none of which are particularly useful for initiating multiple parallel sequential table scans. Implementing the software alternative on a mainframe platform required developing custom systems-level software for the purpose, which some large organizations facing this problem have done. SMP machines continue to be designed primarily for on-line processing and characteristically demonstrate very low data bandwidth in practice, which makes them generally unsuitable for any large application of this type.
MPP hardware is a workable solution, but it also presents some technical and economic challenges. In many cases, the high volume data that will populate the warehouse already is resident on the mainframes where it was captured in the first place. Duplicate copies of all event, reference, and code-set files must be maintained in both environ-ments. Interactive applications often have to be maintained in both environments to access the same basic data. Businesses with the fixed cost of a large mainframe infrastructure behind them are reluctant to take on the burden of a second environment, including new skills require-ments. And it costs millions of dollars to buy capacity sufficient for making batch processing windows, which for the most part sits idle because of the limited purpose nature of the technology.
Over the last several years, however, mainframe CPU, disk, tape, and software prices have come down dramatically. In the early 1990s, mainframe CPU power cost over $100,000 per MIPS (million instructions per second). Today, mainframes are being made using the cheaper CMOS technology, and mainframe CPUs can be purchased in the $14,000 per MIP range. High performance tape and disk devices are available at comparable prices regardless of platform.
Price Waterhouse also has developed parallel processing software that permits parallel sequential table scans to be initiated in mainframe data warehouse applications without requiring systems programmer intervention. This software is known as Geneva V/T and generally offers 10-50 fold CPU consumption and throughput gains over baseline COBOL and DB2 techniques. The combination of a more than five-fold reduction in price of the basic hardware and a ten-plus factor increase in throughput and compute efficiency from the Geneva V/T parallel software has turned around the basic cost/performance calculations in favor of the mainframe for these types of data warehouse applications.
How can you tell which approach is best for a given situation?
Evaluating a mainframe software approach first for exploiting parallel processing offers some substantial advantages. Geneva V/T can support processing from tape as well as disk, which means that historical event data can be accessed directly from existing datasets without the need to buy additional hardware just to get started. This permits conducting a mainframe proof-of-concept demonstration to verify that the data being considered for warehousing truly is valuable for resolving pressing problems and to prove the processing metrics for the case at hand in the existing production environment.
Assuming that access to the data proves to be truly valuable, use in an operational context may necessitate the purchase or allocation of additional compute and disk/tape resources. But, because new resources simply will be added to the existing SYSPLEX configuration in most cases, peak load requirements probably can be accommodated through scheduling rather than outright purchase of excess capacity necessary to get through the humps. This most likely will result in a substantially lower overall net hardware purchase compared with what would be required if an MPP hardware approach were adopted. In addition, during periods when high volume data warehouse files are not being processed, whatever additional hardware is purchased is available for other applications experiencing peak-load demands.
What does a top-down picture of this mainframe environment look like?
An graphic view of what we refer to as the MVS Operational Data Store Architecture is provided in the diagram below:
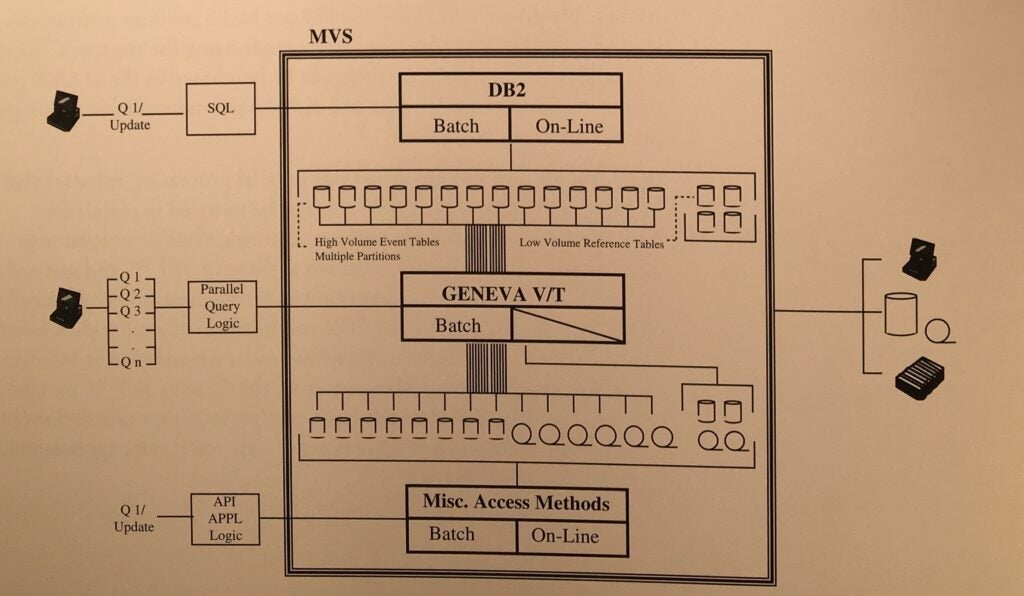
DB2 provides a complete relational database environment for transaction processing applications and intermediate volume on-line and batch extract/reporting processes. Where high volume parallel processing techniques are appropriate, Geneva V/T provides the mechanism for accessing on-line DB2 and VSAM files in place and sequential files on either disk or tape. Where interactive queries are required, DB2 provides the framework for interactive execution. Where volume problems dictate minimizing the number of times datasets are accessed, Geneva V/T provides for a generalized single pass architecture where multiple queries are resolved simultaneously in one pass of the data.
The Geneva V/T disk or tape option is especially important since new tape technology is now available with 30 gigabyte (compressed) capacity per volume and I/O transfer rates in the 20 megabytes per second range (most high performance disk transfer rates are in the 6 megabytes per second range). This means that for high volume event files where sequential processing is the preferred method, dramatically cheaper tape becomes the preferred media for storage, not just a compromise forced by economics. This can offer significant potential for dramatic savings over an MPP hardware approach that would dictate DASD-based secondary storage.
Recently released new features of MVS also make the mainframe environment the most attractive choice as the backbone server for a client/server network. Especially important facilities are the LANRES and LANSERVER MVS functions. Files generated by selection functions, either directly from DB2 or Geneva V/T, can be stored in a common workstation-oriented file repository on mainframe attached DASD or automatically downloaded to designated servers on the WAN/LAN. EBCDIC/ASCII translations are performed automatically and NetWare users can access mainframe storage devices just like any other NetWare disk volume. Options for accessing mainframe files through the Internet are even available.
* * *
In summary, the mainframe world has changed. Instead of being something to run away from because of cost, absence of software, or lack of connectivity and GUI options, it now is in principle the server platform of choice. No doubt there will be many situations where other server or specialty processor platform choices will be appropriate. But, instead of “getting off the mainframe” being the going in position, “exploiting the already existing mainframe infrastructure” should be the common sense point of departure when evaluating technical platform alternatives for parallel processing problems.
[1]DB2 does take advantage of some parallel processing techniques under certain circumstances.
Original Image
The following are images of the original paper.







