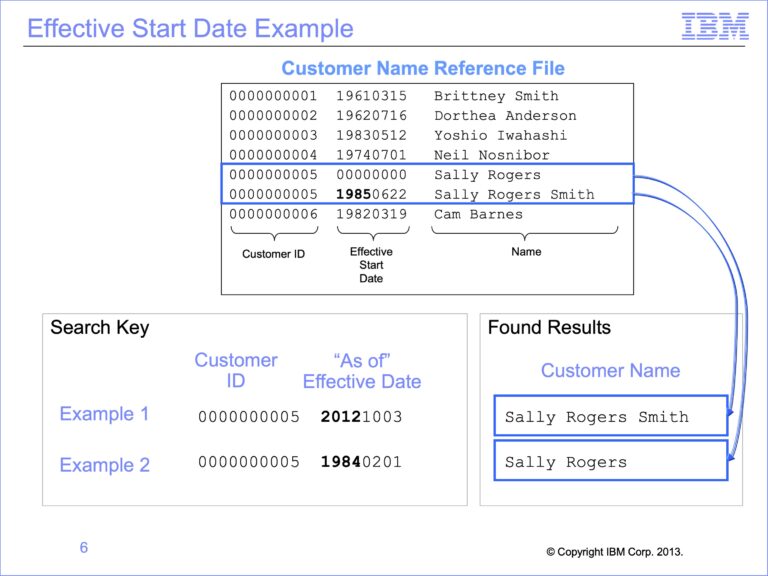
Training Module 16: Effective Dated Lookups
The slides used in the following video are shown below: Slide 1 Welcome to the training course on IBM Scalable Architecture for Financial Reporting, or SAFR. This is Module 16,...

The slides used in the following video are shown below: Slide 1 Welcome to the training course on IBM Scalable Architecture for Financial Reporting, or SAFR. This is Module 16,...
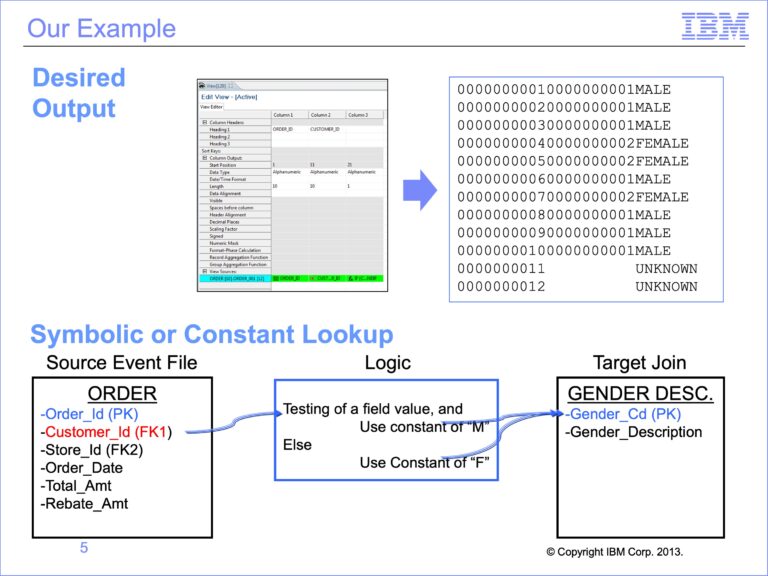
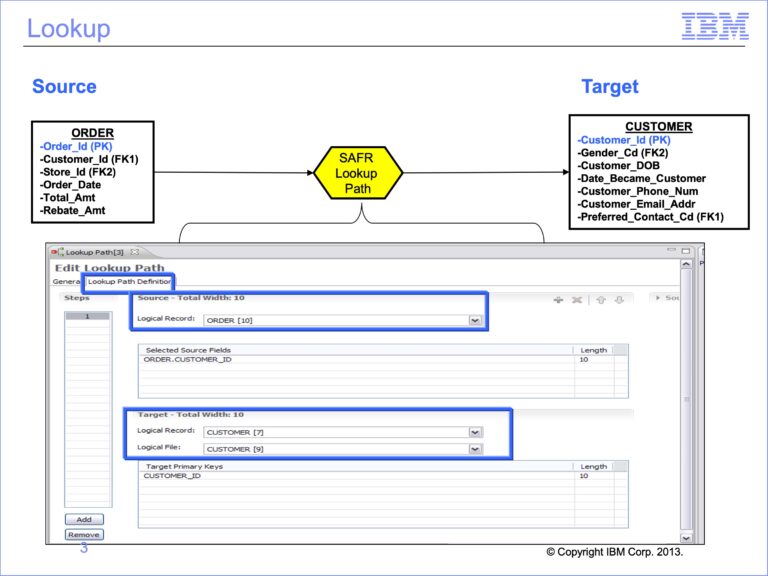
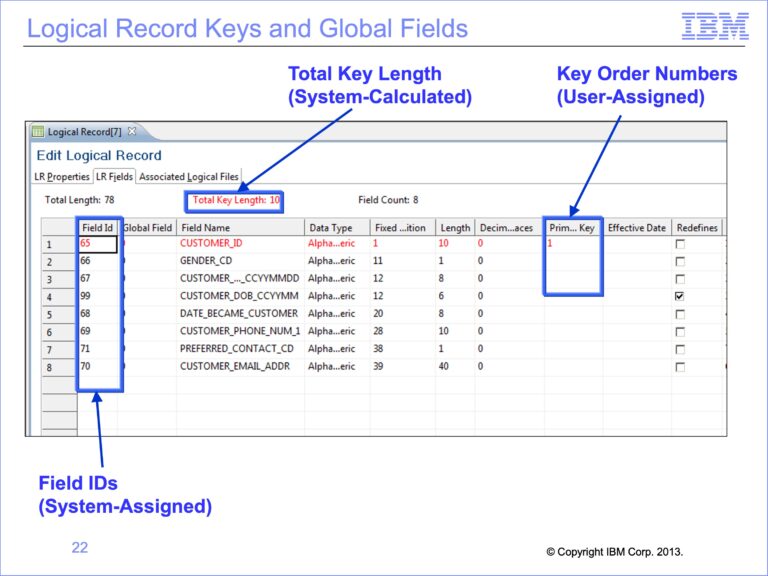
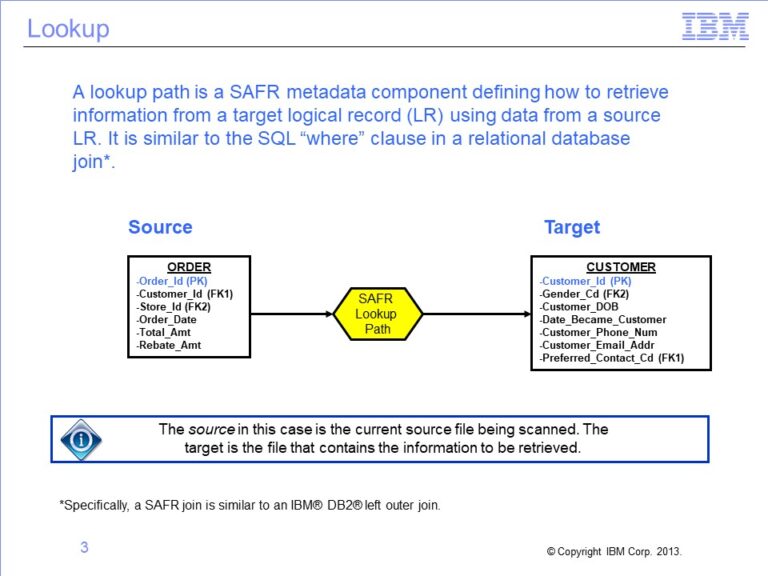
The slides used in this video are shown below: Slide 1 Welcome to the training course on IBM Scalable Architecture for Financial Reporting, or SAFR. This is Module 15, Lookups...
The slides for this video are shown below: Slide 1 Welcome to the training course on IBM Scalable Architecture for Financial Reporting, or SAFR. This is Module 14, Multi-Step Lookups...
The slides used in the following video are shown below: Slide 1 Welcome to the training course on IBM Scalable Architecture for Financial Reporting, or SAFR. This is Module 13,...
The slides used in this video are shown below: Slide 1 Welcome to the training course on IBM Scalable Architecture for Financial Reporting, or SAFR. This is module 9, “Metadata...
The slides of this video are shown below: Slide 1 Welcome to the training course on IBM Scalable Architecture for Financial Reporting, or SAFR. This is module 4: Introduction to...


© 2026 GenevaERS. Copyright © Open Mainframe Project. The Linux Foundation® . All rights reserved. The Linux Foundation has registered trademarks and uses trademarks. For a list of trademarks of The Linux Foundation, please see our Trademark Usage page. Linux is a registered trademark of Linus Torvalds. Privacy Policy and Terms of Use.