

The slides used in this video are shown below:
Slide 1

Welcome to the training course on IBM Scalable Architecture for Financial Reporting, or SAFR. This is module 8: “Common Errors Encountered When Running the Performance Engine.”
Slide 2

This module provides you with an overview of common errors encountered when running the SAFR Performance Engine. Upon completion of this module, you should be able to:
- Diagnose and resolve common Performance Engine errors,
- Set output record limits to assist in debugging, and
- Analyze the relationships between components using the Dependency Checker.
Slide 3

Under normal circumstances, the SAFR Performance Engine transforms data and provides useful outputs. However, if a Performance Engine program detects an unusual condition, it will display an error message. Errors can occur for many different reasons.
Recall that the SAFR Performance Engine consists of six phases. Each phase creates data sets that are read by subsequent phases. If the JCL that executes a program does not point to the data set that the program is expecting, or if it is missing a needed data set, an error is reported.
Errors can also occur if keywords in JCL parameters are missing or misspelled. On the following slides, we’ll cover the most common error conditions and describe how to remedy them.
Slide 4

Recall that the Select phase produces a control report named MR86RPT, or the MR86 Report. This control report contains useful statistics for the current run and, if an error occurs, an error message to help you diagnose the problem.
Slide 5

A view must be active and saved to the Metadata Repository to be selected by the MR86 program. If it is not, an error message is displayed in the MR86 Report, specifying the view number and name.
To remedy this problem, find the view in the Workbench, activate the view, save it, and then rerun the job.
Slide 6

The MR86 program looks for views only in the environment specified by the ENVIRONMENTID parameter in the MR86 configuration file. If the MR86 Report displays a message saying that no views can be found, the problem is often that the wrong environment has been specified there. This value must match the value that is displayed in the Workbench status line, which is the bottom line of the Workbench window. We can see here that the true environment ID is 7 and the value for ENVIRONMENTID in the JCL is 7777, which is a typographical error. In such cases, you correct the ENVIRONMENTID value in the configuration parameters and rerun the job.
Slide 7

For the MR86 program to find your views, the database connection parameters in the MR86 configuration file must be specified correctly. One connection parameter is the schema. The value of the schema parameter must match the value that is labeled as “database” in the Workbench status line. In this example, the schema value is SAFRTR01, but the SCHEMA parameter is SAFRTR01XXXX. Because these two values do not match, a database error is displayed in the MR86 Report. In such cases, you should correct the SCHEMA value in the configuration parameters and rerun the job.
Slide 8

In the Compile phase, the MR84 program reads the XML file created by the prior step and converts it to a form that can be executed by the Extract phase later. This process, called compiling, checks for syntax errors and other errors in the XML file and displays associated messages in the MR84 Report. This report seldom displays any error messages because under normal circumstances, views that are read by the MR84 program have already been compiled by the Workbench. If you encounter a problem in this phase, report it to SAFR Support.
Slide 9

In the Logic phase, the MR90 program reads the VDP file created by the prior step and converts it into data sets that are used later by the Reference phase and the Extract phase. Errors that occur in this phase are rare and are usually the result of database corruption. If you encounter a problem in this phase, report it to SAFR Support.
Slide 10

In the Reference phase, the MR95 program converts reference data into a form that is appropriate for lookup operations that are executed subsequently in the Extract phase. MR95 produces a control report known as the MR95 Report, which either indicates successful completion or displays errors that must be corrected before proceeding.
Slide 11

The view shown here reads the ORDER_001 logical file and displays data from two lookup fields: CUSTOMER_ID and NAME_ON_CREDIT_CARD.
Slide 12

We can see from the column source properties that the CUSTOMER_ID field receives its value from data accessed by the CUSTOMER_from_ORDER lookup path.
Slide 13

We can also see from the column source properties that the NAME_ON_CREDIT_CARD field receives its value through a different lookup path named CUSTOMER_STORE_CREDIT_CARD_INFO_from_ORDER.
Slide 14

If the JCL for the Reference job does not contain DD statements for all reference files needed to support the selected views, the job terminates with an abnormal end (or “abends”). The MR95 Report displays a message with the DD name of the missing file, which in this case is CUSTCRDT.
Slide 15

The error condition in this case can be remedied by adding the CUSTCRDT file to the JCL and rerunning the job.
Slide 16

The Reference Extract Header (or “REH”) file, with a DD name of GREFREH, is required for the Reference phase to function correctly. If the DD statement for the REH file is missing, an error message is displayed in the MR95 Report, saying that the DCB information for the file is missing. To remedy the problem, add the DD statement for GREFREH to the JCL and rerun the job.
Slide 17

Similarly, a Reference Extract Detail (or “RED”) file associated with every lookup path is required for the Reference phase to function correctly. DD names for RED files begin with the letters “GREF” and end with a 3-digit number. If the DD statement for a RED file is missing, an error message is displayed in the MR95 Report, saying that the DCB information for the file is missing. In this case, the GREF004 file is missing. To remedy the problem, add the DD statement for GREF004 to the JCL and rerun the job.
Slide 18

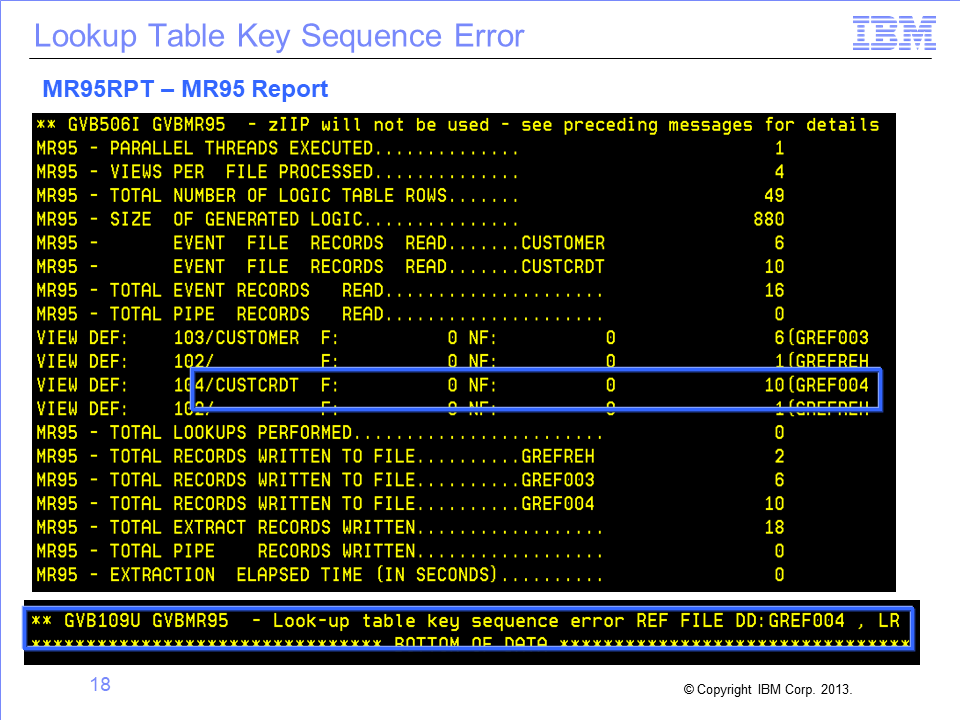
For reference files to function correctly in SAFR, there are two rules which must be followed:
- First, records must have unique keys
- And second, records must be sorted in key sequence.
If either of these rules is broken, a “lookup table key sequence” error message is displayed in the MR95 Report. To resolve the problem, we must first examine the error message and note the DD name associated with the reference work file in error. In this case, the DD name is GREF004. We can then use this to find the DD name of the source reference file. Scanning upwards in the MR95 Report, we can see that GREF004 is written using records read from the DD name CUSTCRDT.
Slide 19

To research this problem further, we must find the length of the key associated with the logical record for customer credit card Info. In this case, it is 10. We must also find the data set associated with the DD name CUSTCRDT. From the JCL, we can see that it is GEBT.TRN.CUSTCRDT.
Slide 20

If we open the data set GEBT.TRN.CUSTCRDT on an ISPF Edit screen, we can see that records 5 through 9 all have the same key value. But rule #1 stated that each key must be unique. We can also see that the records are not in key sequence, which breaks rule #2. To solve our original problem, we remove the duplicate records and sort the records in key sequence. Doing this and then rerunning the job will remove the error condition.
Slide 21

Sometimes when you are debugging a problem, it is useful to limit the number of records written to an extract file. You can set such a limit in the Workbench on the Extract tab of the View Properties screen for a view. Processing for the view will stop after the specified number of records is written. Remember, you must rerun from the Select phase to incorporate the view changes into the Extract phase.
Slide 22

You can set a similar limit for the final output file that is written in the Format phase. You can set such a limit in the Workbench on the Format tab of the View Properties screen for a view. Processing for the view will stop after the specified number of view output records is written. Again, you must rerun from the Select phase to incorporate the view changes into the Format phase.
Slide 23

The Dependency Checker is a useful tool for debugging views. You can select it from the Reports menu of the Workbench.
Slide 24

In this example, you want to see all direct dependencies for view #71. First, select the appropriate environment, and then select the component type, which in this case is View. Then select view #71 from the list.
For debugging purposes, we normally select the Show direct dependencies only check box. Clearing the check box would cause indirect dependencies to be displayed, too, and this is typically useful only when an impact analysis is needed for a project.
Slide 25

After clicking Check, you see a hierarchical list of all the SAFR metadata components that are used by the view. This helps you determine whether any components that should not have been referenced are referenced and whether any components are missing. Portions of the list can be expanded by clicking the plus sign or collapsed by clicking the minus sign.
Slide 26

In the Extract phase, MR95 executes a series of operations that are defined in the Extract Logic Table, or XLT. The MR95 Trace function causes these operations to be written to a report to aid you in debugging a view. The Trace function can be selected and configured in MR95PARM, the MR95 parameter file.
Trace can be used to diagnose many SAFR problems:
- LR problems
- Lookup problems
- View coding errors, and
- Data errors
The Trace function will be described in detail in an advanced SAFR training module.
Slide 27

When you are developing a view, you should apply several guidelines to make your work more efficient.
Begin by coding a small subset of the requirements for a view, and then testing that. For example, you may choose to code a view with only a small number of columns or a smaller record filter. Once you have successfully gotten this view to work, you can add more complexity and continue until the view is complete.
It is useful to start testing with only a small number of records. In this way, you can more easily see the results of your view logic.
Verify that the output format for each column is correct. If it isn’t, review the column properties.
Check to make sure that the number of records written is what you expected. If it isn’t, check the record filters to verify that the logic is correct.
Finally, verify that the output value for each column is correct. If it isn’t, examine the column logic.
Slide 28

This module provided an overview of common errors encountered when running the SAFR Performance Engine. Now that you have completed this module, you should be able to:
- Diagnose and resolve common Performance Engine errors
- Set output record limits to assist in debugging, and
- Analyze the relationships between components using the Dependency Checker
Slide 29

Additional information about SAFR is available at the web addresses shown here.
Slide 30

Slide 31

This concludes the Module 8. Thank you for your participation.

