

The following is an R&D effort to define the next generation of SAFR, composed by Kip Twitchell, in March 2017. It was not intended to be a formally released paper, but the ideas expressed herein have continued to resonate with later assessments of the tool direction.
Proposal for Next Generation SAFR Engine Architecture
Kip Twitchell
March 2017
Based upon my study the last two month, in again considering the next generation SAFR architecture, the need to separate the application architecture from the engine architecture has become clear: the same basic combustion engine can be used to build a pump, a generator, a car or a crane. Those are applications, not engines. In this document, I will attempt to outline a possible approach to the Next Generation SAFR engine architecture, and then give example application uses after that.
This document has been updated with the conclusions from a two day workshop at SVL in the section titled “Conclusions” after the proposal in summary.
Background
This slide from Balancing Act is perhaps a simple introduction to the ideas in this document:
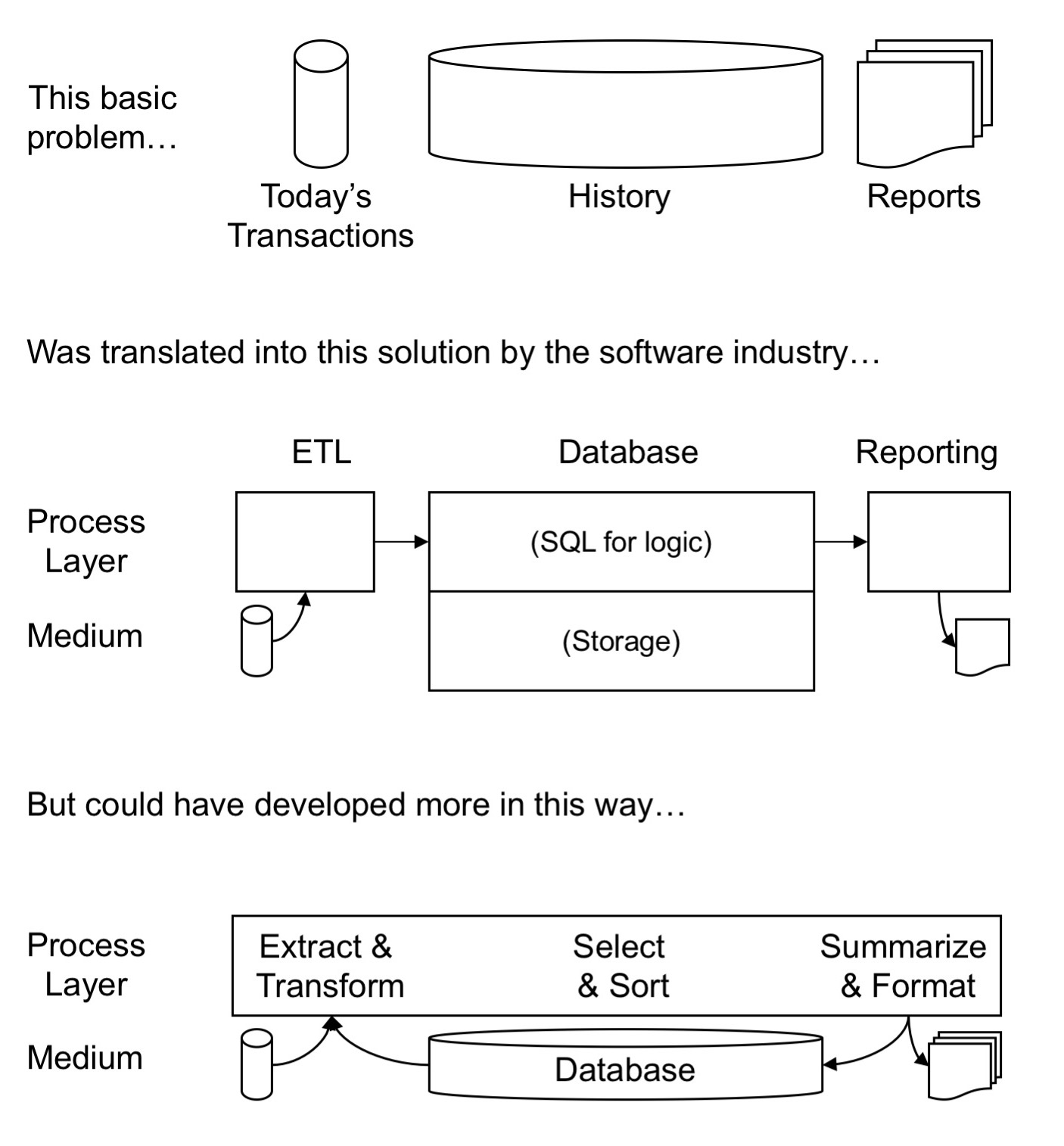
(from Balancing Act, page 107)
Key SAFR Capabilities
The SAFR architecture recognizes that building balances from transactions is critical to almost all quantitative analytical and reporting processes. All financial and quantitative analytics begins with a balance, or position. Creating these is the key SAFR feature.
Additionally, SAFR enables generation of temporal and analytical business events in the midst of the posting process, and posts these business events at the same time. In other words, some business events are created from outstanding balances. SAFR does this very effectively.
Third, the rules used to create balances and positions sometimes change. SAFR’s scale means it can rebuild balances when rules change; for reclassification and reorganization problems, changes in required analyses, or new, unanticipated analyses.
Fourth, SAFR’s high speed join capabilities, especially date effective joins, and the unique processing model for joins on high cardinality, semi-normalized table structures creates capabilities not available in any other tool.
Last, the ability to do all these things in one pass through the data, post initial transactions, generated new transactions, reclassify some balances or create new ones, and join all the dimensions together, along with generating multiple outputs, and do so efficiently, creates a unique set of functions.
This combined set of features is what is enable by the bottom diagram.
Key SAFR Limitations
SAFR has often been associated with posting or ETL processes, which are typically more closely aligned with the tail end of the business event capture processes. It also has association with the report file generation processes at the beginning of the other end of the data supply chain. It has done so without fully embracing either ends of this spectrum: It has attempted to provide a simplified user interface for reporting processes which was not completely a language to express posting processes, and it has not integrated with SQL, the typical language of reporting processes.
The idea behind this paper is that SAFR should more fully embrace the ends of these spectrums. However, to be practical, it does not propose attempting to build a tool to cover end-to-end data supply chain, the scope of which would be very ambitious. Covering the entire data supply chain would require building two major user interfaces, for business event capture and then reporting or analysis. The approach below contemplates allowing most of the work on either of these interfaces to be done by other tools, and allowing them to use the SAFR engine, to reduce scope of the work involved.
This paper assumes an understanding of how SAFR processes today to be briefer in writing. This document is intended for an internal SAFR discussion, not a general customer engagement.
Proposal in Summary
In summary, SAFR should be enhanced as follows:
Overall
1) The SAFR engine should be made a real-time engine, capable of real time update and query capabilities
2) It should also be configurable to execute in a batch mode if the business functions require (system limitations, posting process control limitations, etc.).
Posting Processes
3) The existing workbench should be converted or replaced with a language IDE, such as Java, Java Script, Scala, etc. The compile process for this language would only permit a subset of the total functions of those languages that fit in the SAFR processing construct.
4) When the engine is executed in “Compiled Code” mode, (either batch or real time), it would generally perform functions specified in this language, and the logic will be static.
5) Real-time mode application architecture would typically use SAFR against indexed access inputs and outputs, i.e., databases capable of delivering specific data for update, and applying updates to specific records.
Reporting Processes
6) SAFR should have a second logic interpreter in addition to the language IDE above, and accept SQL as well. This would generally be used in an “Interpreted Logic” mode.
7) To resolve SQL, SAFR would be a “bypass” SQL interpreter. If the logic specified in SQL can be resolved via SAFR, the SAFR engine should resolve the request.
8) If SAFR cannot satisfy all the required elements, SAFR should pass the SQL to another SQL engine for resolution. If the data is stored in sequential files, and SAFR is the only resolution engine available, and an error would be returned.
Aggregation and Allocation Functions
9) SAFR functionality should be enhanced to more easily perform aggregation and allocation functions.
10) This may require embedded sort processes, when the aggregation key is not the natural sort order of the input file.
11) A more generalized framework for multiple level aggregation (subtotals) should be considered, but may not be needed in the immediate term.
12) Additionally, a generalized framework for hierarchy processes should also be contemplated.
Workshop Conclusions:
In the two day workshop I made the point that the z/OS version of SAFR does not meet the requirements of this paper; and the SAFR on Spark version did not as well. Beyond this, the workshop concluded the following:
(1) The existing SAFR GUI and its associated meta data tables, language, and XML are all inadequate to the future problems, because the GUI is too simple for programming—thus the constant need for user exits—and it is too complex for business people—thus one customer built RMF;
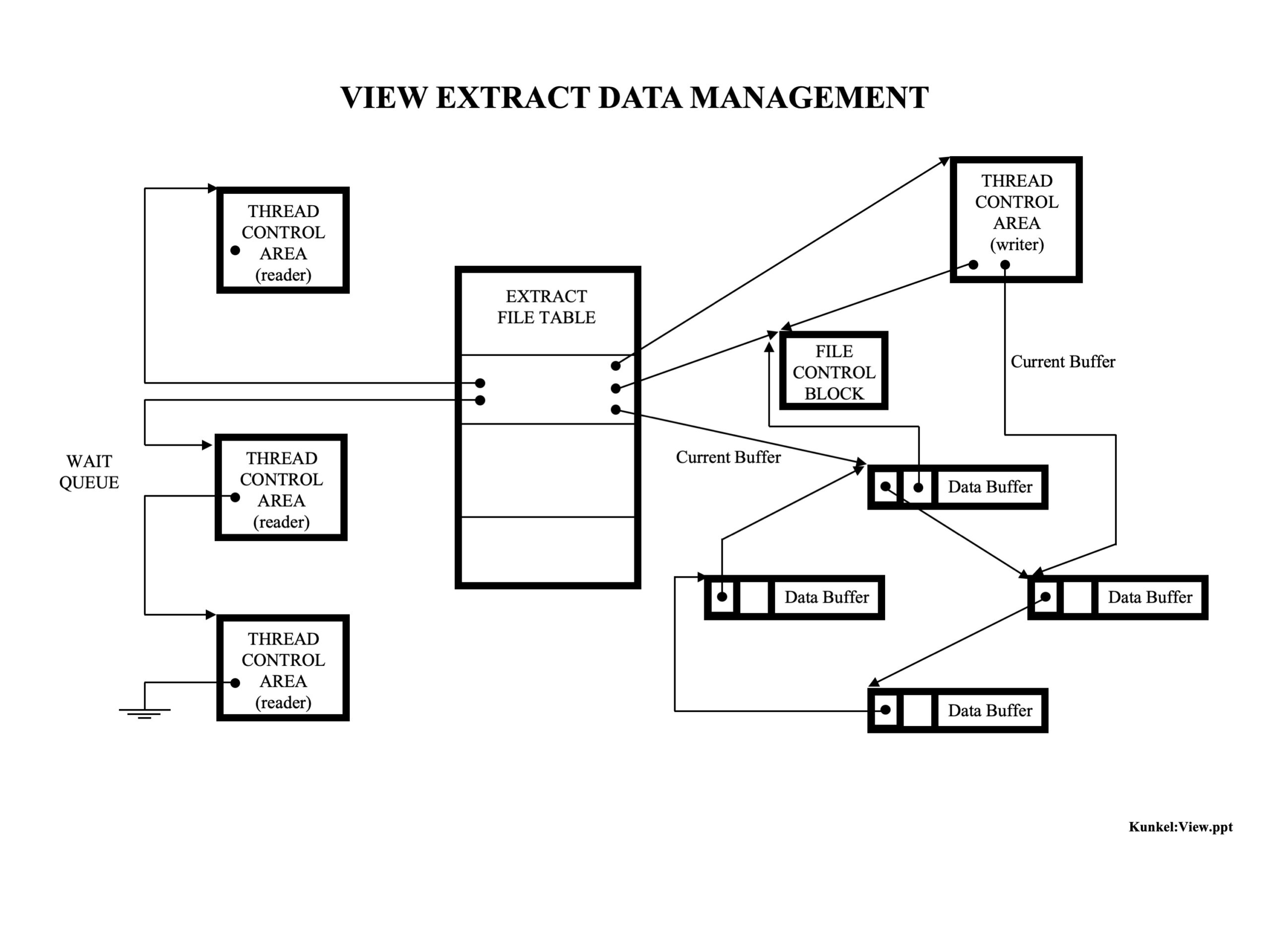
(2) The database becomes a problem in the traditional architecture because there is this explosion of rows of data in the LR Buffer which then collapses down to the answer sets, but the database in the middle means it all has to get stored before it can be retrieved to be collapsed.
(3) Platform is not an issue considered in this paper, and that the experience of both existing customers seems to demonstrate there is something unique in SAFR that other tools do not have.
(4) We agreed that although the point about the data explosion and the database in the middle being a problem, taking on the SQL interpretation mode was a bridge too far; we should let the database do the work of satisfying the queries. SAFR can still produce views which selects and aggregates data to be placed in the database for use, as it has historically.
(5) Stored procedures are just too simplistic for the kinds of complex logic in a posting process; so, we need to build something outside the database which can access the database for inputs and for storing outputs.
(6) There is not a good reason to require the programmer to go clear to a procedural language to specify the SAFR process; The SAFR on Spark POC SQL is a declarative language that does not put as much burden on the developer.
(7) It is possible to use in-line Java code within the SAFR on Spark prototype when a procedural language is required. This could eliminate simple user exits.
(8) Spark is a good framework for a distributed work load; z/OS manages the parallel processes very effectively, but requires a big server to do so. Using another language on another platform would require building that distribution network. That is expensive.
(9) The real time capabilities would simply require creation of a daemon that would then execute the SAFR on Spark processes whenever needed. This is nearly a trivial problem; performance and response time notwithstanding.
(10) We do not have enough performance characteristics to say if the Spark platform and the prototype will scale for any significant needs.
Real-time Engine and IO Models
The following table outlines likely processing scenarios:
| Real-time Mode | Batch Mode | |
| Input Types | Database Messaging Queue | Sequential files or Database or Messaging Queue |
| Output Types | Database or Messaging Queue or Sequential Files | Sequential Files |
Sequential files in this table included native Hadoop structures. Output from batch mode files could be loaded into databases or messaging queues beyond SAFR processing, as is typically done today with SAFR.
Recommendation: SAFR today recognizes different IO routines, particularly on input. It has an IO routine for sequential files, DB2 via SQL, VSAM, DB2 via VSAM. It has had prototype IMS and IDMS drivers. This same construct can be carried forward into the new version, continuing to keep separate the logic specification from the underlying data structures, both inbound and outbound. New data structure accesses can be developed over time.
Enhancement: An additional processing approach could be possible but less likely except in very high volume situations: Real-time mode against input sequential files. In this configuration, SAFR could continually scan the event files. Each new request would jump into the ongoing search, noting the input record count of where the search begins. It would continue to the end of the file, and through the loop back to the start of the file, continuing until it reaches the starting record count again, and then end processing for that request. This would only be useful if very high volumes of tables scans and very high transaction volumes made the latency in response time acceptable.
Impediments: The challenges to a real-time SAFR engine is all the code generation interpretation processes in the performance engine. Making these functions very fast from their current form would be difficult. Using an IDE for logic specification has a much better chance of making the performance possible. Performance for the interpreted mode would require significant speed in interpretation and generation of machine code from the SQL logic.
Compiled Code Mode
Background: Major applications have been built using SAFR. The initial user interface for SAFR (then called Geneva, or 25 years ago) was intended to be close to an end user tool for business people creating reports. The Workbench (created starting in 1999) moved more and more elements away from business users, and is now wholly used only by IT professionals.
Additionally, because of the increasingly complex nature of the applications, additional features to manage SAFR views as source code have been developed in the workbench. These include environment management, and attempts at source code control system integration. These efforts are adequate for the time, but not highly competitive with other tools.
SAFR’s internal “language” was not designed to be a language, but rather, only provide logic for certain parts of a view. The metadata constructs provide structures, linkage to tables or files, partitioning, join logic. The view columns provide structure for the fields or logic to be output. The SAFR language, called Logic Text, only specifies logic within these limited column and general selection logic.
Recommendation: Given the nature of the tool, it is recommended SAFR adopt a language for logic specification. I would not recommend SQL as it is not a procedural language, and will inhibit new functionality over time.
The fundamental unit for compile would be a Pass or Execution, including the following components:
- A Header structure, which defines the meta data available to all subprograms or “method”. It would contain:
- The Event and lookup LR structures
- The common key definition
- Join paths
- Logical Files and Partitions
- Available functions (exits)
- A View Grouping structure,
- Defining piping and token groups of views.
- Tokens and similar (new) functions could potentially be define as In-line (or view) function calls (like tokens) which can be used by other views.
- Each view would be a method or subprogram that will be called and passed each event file record
The final completed Execution code could be compiled, and the resulting executable managed like any other executable; the source code could be stored in any standard source code control library. All IT control and security procedures could follow standard processes. This recognizes the static nature of most SAFR application development processes.
Although this approach offloads some portion of the user interface, language definition, and source code management issues, the next gen SAFR code base would have to include compilers for each platform supported. Additional SAFR executables would be IO modules, and other services like join, common key buffer management, etc. for each platform supported.
Impediments: A standard IDE and language will likely not include the Header and Grouping structure constructs required. Can a language and IDE be enhanced with the needed constructs?
Interpreted Logic Mode
Background: Certain SAFR processes have been dynamic over the years, in various degrees. At no time, however, has the entire LR and meta data structure definition been dynamic. In the early days, the entire view was dynamic in that there were fairly simple on-line edits, but some views were disabled during the production batch run. In more recent years fewer pieces have been dynamic. Reference data values have always been variable, and often been used to vary function results, in the last two decades always from externally maintained systems like ERP systems. Most recently, new dynamic aspects have been bolted on through new interfaces to develop business rules facilities.
The SAFR on Spark prototype application demonstrated the capability to turn SAFR logic (a VDP, or the VDP in XML format) into SQL statements quite readily. It used a CREATE statement to specify the LR structure to be used. It had to create a new language construct, called MERGE to represent the common key buffering construct. SQL tends to be the language of choice for most dynamic processes. SQL also tends to be used heavily in reporting applications of various kinds.
Recommendation: Develop a dynamic compile process to turn SAFR specific SQL into SAFR execution code. This will allow for other reporting tools to gain the benefits of SAFR processes in reporting. If the data to be accessed by SAFR is in a relational database (either the only location or replicated there), SAFR could pass off the SQL to another resolution engine if non-SAFR SQL constructs are used.
Impediments: It is not clear how the MERGE parameters would be passed to the SAFR SQL Interpreter. If sequential files are used for SAFR, would a set of dummy tables in a relational system provide a catalogue structure sufficient for the reporting tool to generate the appropriate reporting requirements? Also, can the cost of creating two compilers be avoided?
Enhancement: CUSTOMER’s EMQ provides a worked example of a reporting application which resolves SQL queries more efficiently that most reporting tool. It uses SQL SELECT statements for the general selection criteria, and the database functions for and sort (ORDER BY), and some aggregation (GROUP BY) functions. When considering SAFR working against an indexed access structure, this construct may be similar. More consideration should perhaps be given.
Compile Code and Interpreted Logic Intersection
Background: The newer dynamic, rules based processes, and the older, more static Workbench developed processes cannot be combined into a single process very easily because of duplicated metadata. This arbitrary division of functions to be performed in Compile Code mode verses Interpretive Mode is not desirable; there may be instances where these two functions can be blended into a single execution.
Recommendation: One way of managing this would be to provide a stub method which allows for calling Interpreted processes under the Compiled object. The IDE for development of the Interpreted Mode logic would be responsible for ensuring conformance with any of the information in the header or grouping structures.
Aggregation and Allocation Processes
Background: Today’s SAFR engine’s aggregation processes are isolated from the main extract engine, GVBMR95, in a separate program, GVBMR88. Between these programs is a sort step, using a standard sort utility. This architecture can complicate the actual posting processes requiring custom logic to table, sort (in a sense, through hash tables) detect changed keys, and aggregate last records before processing new records.
Additionally, today’s SAFR does not natively perform allocation processes, which require dividing transactions or balances by some set number of additional records or attributes, generating new records. Also, SAFR has limited variable capabilities today.
Recommendation: Enhancing SAFR with these capabilities in designing the new engine is not considered an expensive development; it simply should be considered and developed from the ground up.
Next Steps
Feedback should be sought on this proposal from multiple team members, adjustments to it documented, and rough order of estimates of build cost developed.

