Initial Open Source Work: Metadata Translation
Existing customers have been working on using GenevaERS metadata in related processes outside of GenevaERS. Our first contributor to open source, Sandy Peresie, took on the challenge of building a...

Existing customers have been working on using GenevaERS metadata in related processes outside of GenevaERS. Our first contributor to open source, Sandy Peresie, took on the challenge of building a...
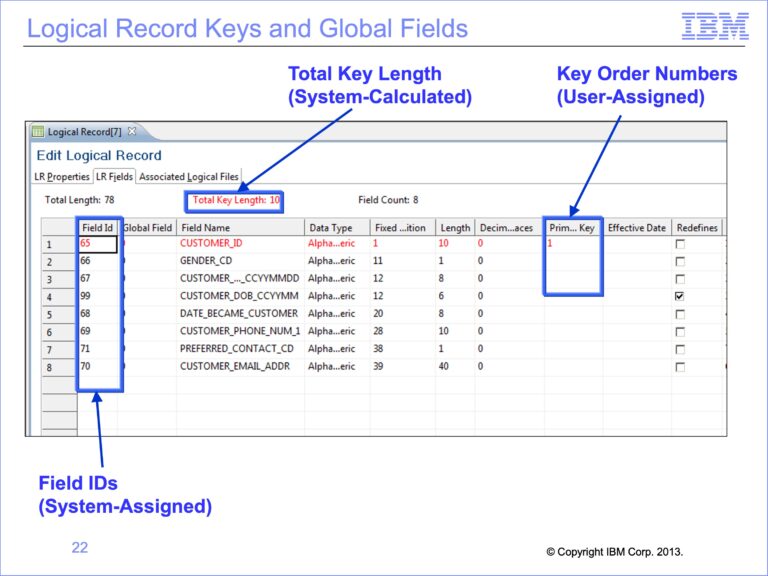
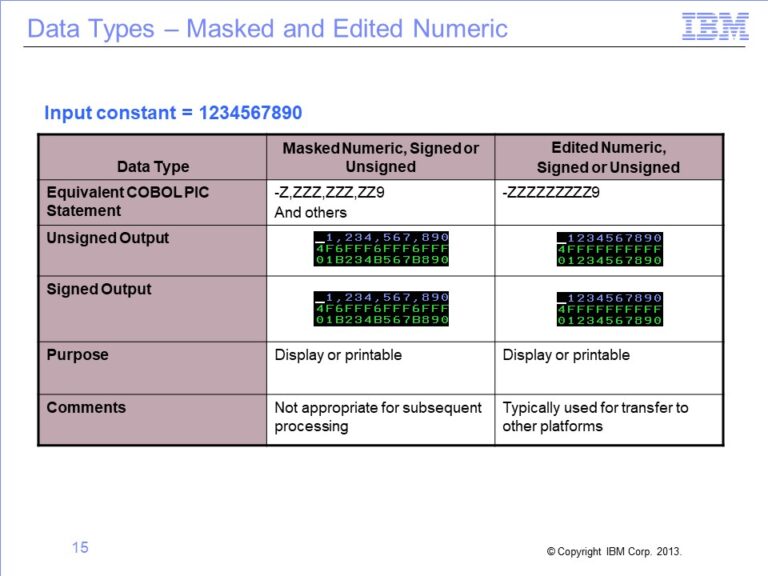
The slides used in this video are shown below: Slide 1 Welcome to the training course on IBM Scalable Architecture for Financial Reporting, or SAFR. This is module 9, “Metadata...
The following slides are used in this on-line video : Slide 1 Welcome to the training course on IBM Scalable Architecture for Financial Reporting, or SAFR. This is module 3:...


© 2026 GenevaERS. Copyright © Open Mainframe Project. The Linux Foundation® . All rights reserved. The Linux Foundation has registered trademarks and uses trademarks. For a list of trademarks of The Linux Foundation, please see our Trademark Usage page. Linux is a registered trademark of Linus Torvalds. Privacy Policy and Terms of Use.